Downtime has a way of surfacing at the worst possible moments: during a product launch, at the peak of a sales campaign, in the middle of a critical data processing window. The instinct after a service comes back up is to move on quickly and treat the incident as closed. The more useful response is to understand exactly what it cost — and whether the architecture that allowed it is still in place.
This article covers what downtime actually costs, what high availability architecture is and is not, and why the economics of building for resilience almost always favour it once the numbers are on the table.
What Downtime Actually Costs
Direct revenue loss is the number most people think of first: if your platform processes $50,000 per hour in transactions and it is down for two hours, the immediate loss is $100,000. But direct revenue is only part of the picture.
Support costs spike during and after an outage. Engineering teams are pulled from planned work to fight fires. SLA penalties may apply if you have contractual uptime commitments with customers. And the reputational damage — particularly for B2B products where customers depend on your uptime for their own operations — often outlasts the incident itself.
For infrastructure where downtime affects compliance or data integrity, the consequences extend further: regulatory reporting obligations, audit trails, and in some industries, potential liability. A two-hour outage that costs $100,000 in direct revenue can cost several times that when the full picture is accounted for.
What High Availability Actually Means
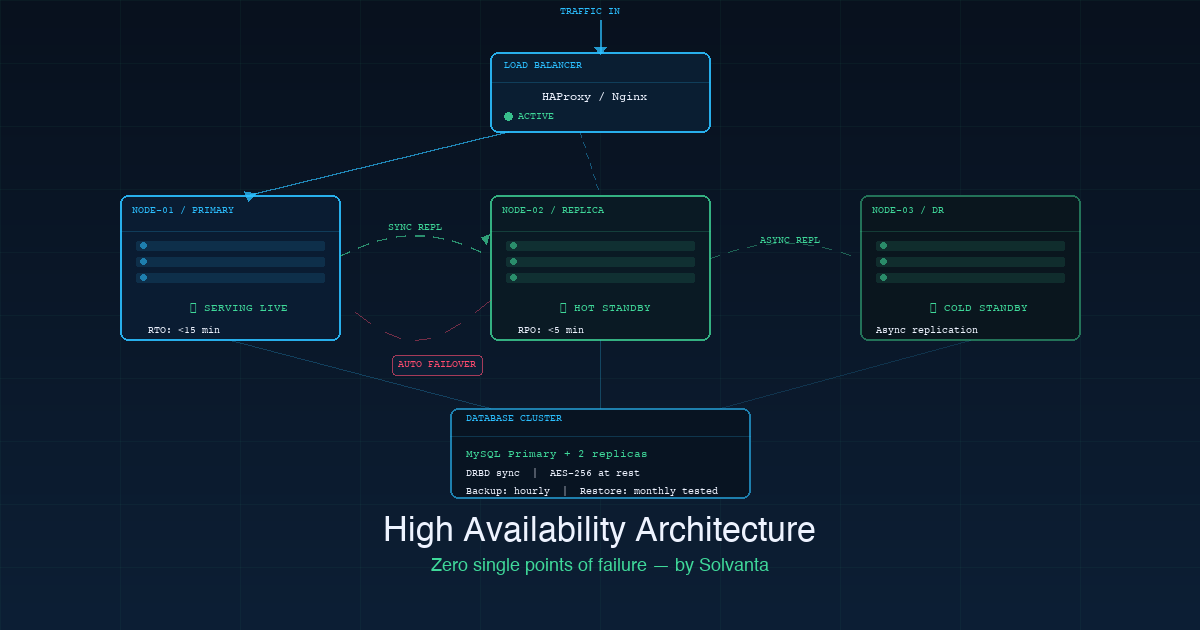
High availability (HA) is a design property of a system, not a feature you toggle on. It means the system continues operating correctly even when individual components fail — hardware dies, a datacenter loses power, a network link drops. The system detects the failure and routes traffic away from the broken component, automatically, without human intervention.
The two metrics that define an HA architecture are:
- RTO (Recovery Time Objective): how long the system takes to recover to a functioning state after a failure. A well-designed HA setup targets sub-15-minute RTO; a highly optimised one can achieve sub-minute automatic failover.
- RPO (Recovery Point Objective): how much data can be lost in the worst case. An RPO of five minutes means that in a catastrophic failure, you lose at most five minutes of data. An RPO of zero requires synchronous replication.
These are not aspirational numbers — they are engineered targets. They require architectural decisions, not just hope.
Common Architectures for High Availability
Active-passive clustering is the most common HA pattern for stateful services. A primary node serves all traffic; one or more standby nodes maintain synchronised state and can take over automatically if the primary fails. Failover is triggered by a heartbeat monitor — Pacemaker and Corosync are standard tooling for this. Correctly configured, failover happens in under a minute without manual intervention.
Active-active clustering goes further: multiple nodes serve traffic simultaneously, each handling a share of the load. If one node fails, the remaining nodes absorb its traffic. This eliminates the switchover window of active-passive and also provides horizontal scaling. The tradeoff is architectural complexity, particularly for stateful services where writes need coordination.
Database replication is the layer most often underengineered in otherwise solid architectures. A replicated MySQL or PostgreSQL setup with automatic failover — using Percona XtraDB Cluster, Patroni, or similar — ensures that the database tier does not become the single point of failure when the application tier is clustered.
Geographic distribution takes HA to a higher threat model: not just component failure within a datacenter, but the entire datacenter going offline. Geographically distributed replicas with asynchronous replication and a well-tested DR runbook mean that a datacenter-level event is recoverable, not catastrophic.
The Cost of Building HA vs. the Cost of Not Building It
The common objection to HA architecture is cost. Running two or three nodes instead of one costs more in infrastructure. The engineering time to design, configure, and test a proper HA setup is not trivial. These are real costs.
But the comparison is not between “HA costs” and “no HA costs.” It is between “HA costs” and “downtime costs, plus HA costs when you eventually build it under pressure after an incident.” Most teams that implement HA architecture do so after an outage that made the business case undeniable. The teams that implement it proactively avoid paying the tuition on that lesson.
For a service generating $10,000 per hour, two major outages per year averaging three hours each adds up to $60,000 in direct revenue loss. An active-passive HA setup for that service — an additional node, a load balancer, and the engineering to wire it together correctly — costs a fraction of that. The numbers work.
What Failover Testing Actually Requires
An HA architecture that has never been tested is not an HA architecture. It is an HA architecture on paper. Failover paths that are theoretically correct regularly fail in practice because of subtle configuration drift, dependency issues, or assumptions that were true at design time and stopped being true later.
At Solvanta, every HA setup we deliver includes a scheduled failover drill cadence — typically quarterly. We deliberately take down the primary node, verify that traffic fails over within the target RTO, confirm that the application behaves correctly under the standby node, and restore normal operation. The drill generates a report. The report closes the loop.
The goal is that when a real failure happens — and it will — the failover is an event that the team has already experienced and documented, not an emergency no one has rehearsed.
Starting the Conversation
If you are running a production service on a single node with no automated failover, the question is not whether you should have HA architecture. It is how long you can afford to wait before you do.
We scope and implement HA setups for a range of architectures — from straightforward active-passive VPS clusters to multi-region database replication with full DR runbooks. The starting point is always a conversation about your actual workload, your current architecture, and your tolerance for downtime. Get in touch to plan your architecture.