El tiempo de inactividad tiene una manera de presentarse en los peores momentos posibles: durante el lanzamiento de un producto, en el pico de una campaña de ventas, en medio de una ventana crítica de procesamiento de datos. El impulso después de que un servicio vuelve a estar en línea es seguir rápidamente y tratar el incidente como cerrado. La respuesta más útil es entender exactamente cuánto costó — y si la arquitectura que lo permitió sigue en su lugar.
Este artículo cubre lo que realmente cuesta el tiempo de inactividad, qué es y qué no es la arquitectura de alta disponibilidad, y por qué la economía de construir para la resiliencia casi siempre la favorece una vez que los números están sobre la mesa.
Lo que realmente cuesta el tiempo de inactividad
La pérdida directa de ingresos es el número en el que la mayoría de la gente piensa primero: si tu plataforma procesa $50,000 por hora en transacciones y está caída durante dos horas, la pérdida inmediata es de $100,000. Pero los ingresos directos son solo parte del panorama.
Los costos de soporte se disparan durante e inmediatamente después de una interrupción. Los equipos de ingeniería son apartados del trabajo planificado para combatir incendios. Pueden aplicarse penalizaciones por SLA si tienes compromisos contractuales de disponibilidad con los clientes. Y el daño reputacional — particularmente para productos B2B donde los clientes dependen de tu disponibilidad para sus propias operaciones — a menudo perdura más que el incidente en sí.
Para infraestructura donde el tiempo de inactividad afecta el cumplimiento normativo o la integridad de datos, las consecuencias se extienden aún más: obligaciones de reporte regulatorio, registros de auditoría y, en algunos sectores, responsabilidad potencial. Una interrupción de dos horas que cuesta $100,000 en ingresos directos puede costar varias veces eso cuando se considera el panorama completo.
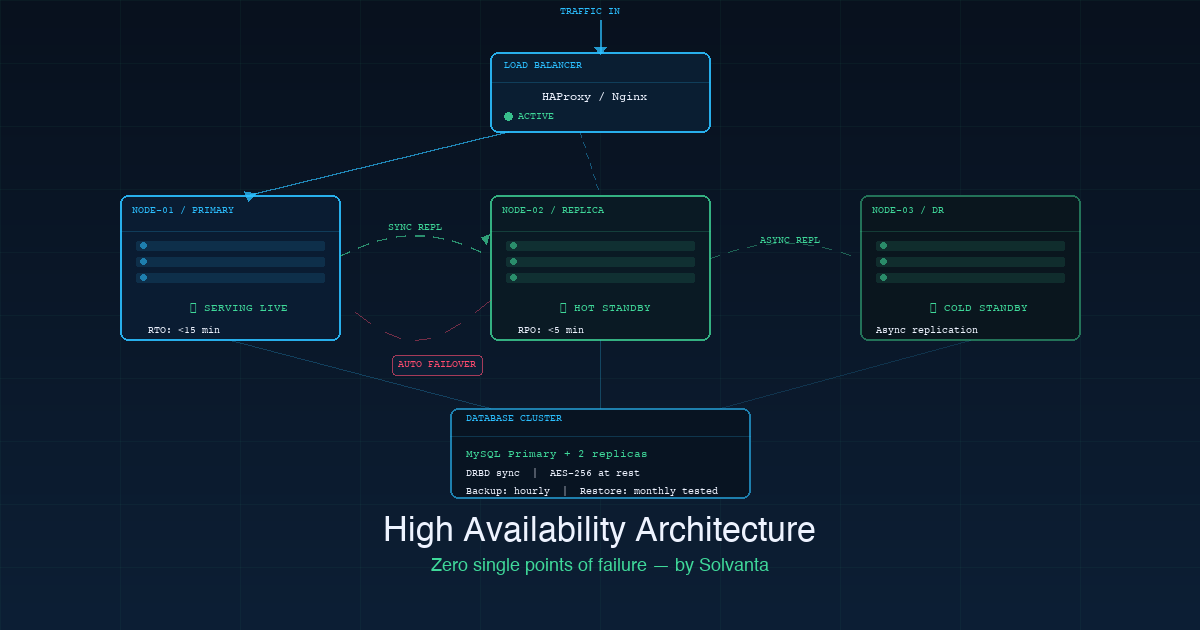
Qué significa realmente la alta disponibilidad
La alta disponibilidad (HA) es una propiedad de diseño de un sistema, no una característica que se activa. Significa que el sistema continúa operando correctamente incluso cuando los componentes individuales fallan — el hardware falla, un centro de datos pierde energía, un enlace de red cae. El sistema detecta el fallo y desvía el tráfico del componente roto, automáticamente, sin intervención humana.
Las dos métricas que definen una arquitectura HA son:
- RTO (Objetivo de Tiempo de Recuperación): cuánto tiempo tarda el sistema en recuperarse a un estado funcional después de un fallo. Una configuración HA bien diseñada apunta a un RTO inferior a 15 minutos; una altamente optimizada puede lograr conmutación automática en menos de un minuto.
- RPO (Objetivo de Punto de Recuperación): cuántos datos pueden perderse en el peor caso. Un RPO de cinco minutos significa que en un fallo catastrófico, se pierden como máximo cinco minutos de datos. Un RPO de cero requiere replicación síncrona.
Estos no son números aspiracionales — son objetivos de ingeniería. Requieren decisiones arquitectónicas, no solo esperanza.
Arquitecturas comunes para alta disponibilidad
El clustering activo-pasivo es el patrón HA más común para servicios con estado. Un nodo primario atiende todo el tráfico; uno o más nodos en espera mantienen el estado sincronizado y pueden tomar el relevo automáticamente si el primario falla. La conmutación se activa mediante un monitor de latido — Pacemaker y Corosync son las herramientas estándar para esto. Correctamente configurada, la conmutación ocurre en menos de un minuto sin intervención manual.
El clustering activo-activo va más lejos: múltiples nodos atienden tráfico simultáneamente, cada uno manejando una parte de la carga. Si un nodo falla, los nodos restantes absorben su tráfico. Esto elimina la ventana de conmutación del activo-pasivo y también proporciona escalado horizontal. La contrapartida es la complejidad arquitectónica, particularmente para servicios con estado donde las escrituras necesitan coordinación.
La replicación de bases de datos es la capa que con más frecuencia se subestima en arquitecturas que de otro modo son sólidas. Una configuración replicada de MySQL o PostgreSQL con conmutación automática — usando Percona XtraDB Cluster, Patroni o similar — garantiza que el nivel de base de datos no se convierta en el único punto de fallo cuando el nivel de aplicación está en clúster.
La distribución geográfica lleva la HA a un modelo de amenaza superior: no solo fallo de componentes dentro de un centro de datos, sino todo el centro de datos fuera de línea. Las réplicas distribuidas geográficamente con replicación asíncrona y un manual de DR bien probado significan que un evento a nivel de centro de datos es recuperable, no catastrófico.
El costo de construir HA vs. el costo de no construirla
La objeción común a la arquitectura HA es el costo. Ejecutar dos o tres nodos en lugar de uno cuesta más en infraestructura. El tiempo de ingeniería para diseñar, configurar y probar una configuración HA adecuada no es trivial. Estos son costos reales.
Pero la comparación no es entre “HA cuesta” y “sin HA no cuesta.” Es entre “HA cuesta” y “costo de tiempo de inactividad, más costo de HA cuando eventualmente la construyes bajo presión después de un incidente.” La mayoría de los equipos que implementan arquitectura HA lo hacen después de una interrupción que hizo el caso de negocio innegable. Los equipos que lo implementan proactivamente evitan pagar la colegiatüra de esa lección.
Para un servicio que genera $10,000 por hora, dos interrupciones importantes al año con un promedio de tres horas cada una suman $60,000 en pérdida directa de ingresos. Una configuración HA activo-pasivo para ese servicio — un nodo adicional, un balanceador de carga y la ingeniería para conectarlo correctamente — cuesta una fracción de eso. Los números funcionan.
Lo que requiere realmente la prueba de conmutación
Una arquitectura HA que nunca ha sido probada no es una arquitectura HA. Es una arquitectura HA en papel. Las rutas de conmutación que son teóricamente correctas fallan regularmente en la práctica debido a una derivación sutil de la configuración, problemas de dependencia o suposiciones que eran ciertas en el momento del diseño y dejaron de serlo más tarde.
En Solvanta, cada configuración HA que entregamos incluye una cadencia programada de simulacros de conmutación — normalmente trimestral. Deliberadamente dejamos fuera de línea el nodo primario, verificamos que el tráfico conmute dentro del RTO objetivo, confirmamos que la aplicación se comporta correctamente bajo el nodo en espera y restauramos la operación normal. El simulacro genera un informe. El informe cierra el ciclo.
El objetivo es que cuando ocurra un fallo real — y ocurrirá — la conmutación sea un evento que el equipo ya haya experimentado y documentado, no una emergencia que nadie ha ensayado.
Comenzando la conversación
Si estás ejecutando un servicio de producción en un solo nodo sin conmutación automática, la pregunta no es si deberías tener arquitectura HA. Es cuánto tiempo puedes permitirte esperar antes de tenerla.
Dimensionamos e implementamos configuraciones HA para una variedad de arquitecturas — desde clústeres VPS activo-pasivo sencillos hasta replicación de bases de datos multiregión con manuales completos de DR. El punto de partida es siempre una conversación sobre tu carga de trabajo real, tu arquitectura actual y tu tolerancia al tiempo de inactividad. Contáctanos para planificar tu arquitectura.