El Objetivo de Tiempo de Recuperación (RTO) y el Objetivo de Punto de Recuperación (RPO) son dos de las métricas más citadas en la planificación de infraestructura. Aparecen en propuestas de proveedores, documentación de cumplimiento y planes de continuidad del negocio en prácticamente todas las industrias. También son, en muchas organizaciones, en gran medida aspiracionales: números que reflejan lo que los equipos esperan que suceda durante un desastre, más que lo que se ha demostrado que sucede.
Un estudio del Consejo de Preparación para Recuperación ante Desastres encontró que el 73% de las empresas están inadecuadamente preparadas para los desastres a pesar de tener planes de recuperación documentados. Esa brecha entre la preparación documentada y la demostrada es uno de los patrones más consistentes que encontramos en el trabajo real de infraestructura.
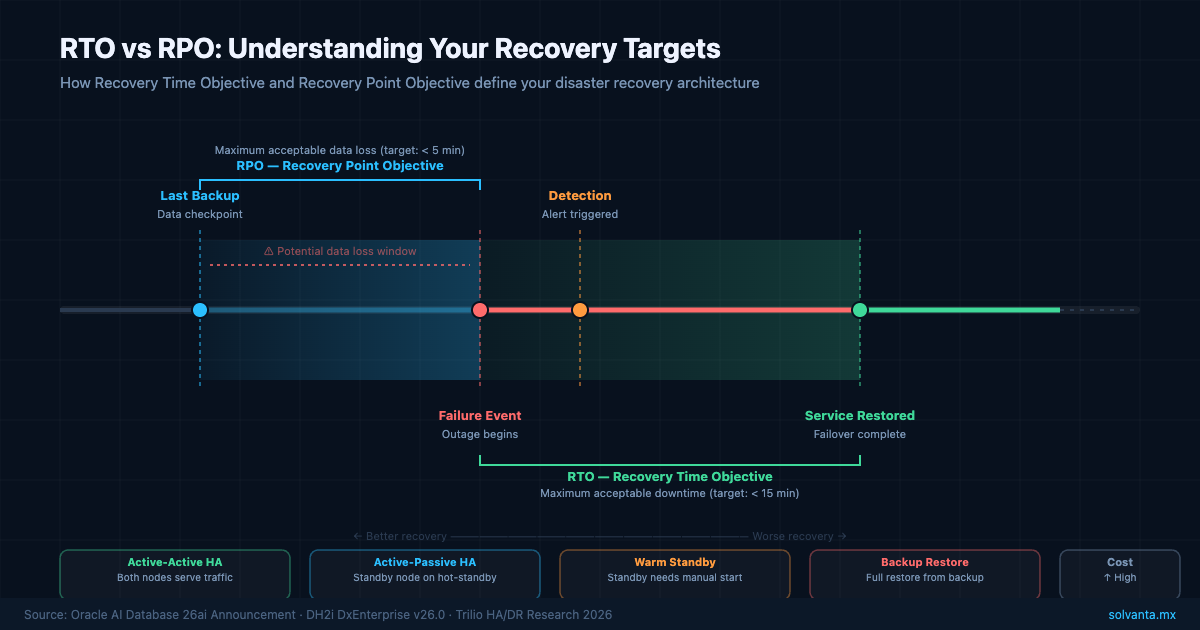
Qué Miden Realmente el RTO y el RPO
El RTO define el tiempo máximo aceptable entre una falla y la restauración del servicio. El RPO define la pérdida máxima aceptable de datos, medida en tiempo, entre el último respaldo o réplica recuperable y el momento de la falla.
Un RTO de 15 minutos significa que tu equipo se compromete a tener los servicios restaurados dentro de un cuarto de hora después de un incidente calificado. Un RPO de 5 minutos significa que no se puede perder más de 5 minutos de datos de forma permanente. Ambas cifras suenan simples hasta que examinas lo que alcanzarlas realmente requiere a nivel de infraestructura.
Un RTO de 15 minutos para un servidor de base de datos implica que el failover es automático, que el nodo en espera ya está sincronizado, que la transferencia de DNS o IP se completa en segundos, y que el nivel de aplicación se reconecta limpiamente, todo sin intervención humana más allá de iniciar el proceso. Si cualquiera de esas suposiciones falla, el reloj del RTO sigue corriendo.
Dónde Suelen Fallar los Planes
El modo de falla más común no es técnico. Es operativo: la arquitectura de failover existe, pero los procedimientos para activarla nunca se han ejecutado en condiciones realistas. Los runbooks se desactualizan. Las credenciales expiran. Un cambio de configuración realizado hace seis meses rompe un supuesto en el que se basaba el plan de recuperación ante desastres. Nadie lo nota hasta que se necesita el plan.
El segundo modo de falla más común es el retraso en la replicación. Muchas organizaciones ejecutan configuraciones de base de datos maestro-réplica y asumen que su RPO es casi cero porque la replicación está configurada. En la práctica, el retraso de replicación bajo carga puede ser significativamente mayor que en condiciones normales, lo que significa que la réplica puede estar más atrasada en el momento exacto en que se activa un failover que en cualquier otro momento.
El reciente anuncio de Oracle sobre su plataforma AI Database 26ai ilustró esto con precisión: su oferta de disponibilidad de nivel Platinum logra tiempos de failover típicos de menos de 30 segundos específicamente porque está diseñada en torno a los modos de falla que hacen que la recuperación ante desastres convencional no cumpla sus objetivos. Lograr un RTO por debajo del minuto a escala requiere decisiones arquitectónicas explícitas, no configuraciones predeterminadas.
Activo-Activo vs. Activo-Pasivo: La Pregunta de Arquitectura
La elección entre el diseño de clúster activo-pasivo y activo-activo tiene implicaciones significativas para los objetivos de RTO y RPO. En una configuración activo-pasivo, el nodo secundario está en espera pero no sirve tráfico. El failover requiere detección, decisión y conmutación, cada uno de los cuales agrega tiempo. En una configuración activo-activo, ambos nodos sirven tráfico y los datos se sincronizan bidireccionalmente. El failover, si ocurre, es a menudo transparente para la capa de aplicación.
Las arquitecturas activo-activo son más complejas de implementar y requieren un manejo cuidadoso de los conflictos de escritura, pero ofrecen el RTO más bajo alcanzable, a menudo medido en segundos en lugar de minutos. Para cargas de trabajo donde el tiempo de inactividad tiene un impacto directo en los ingresos, la inversión en ingeniería generalmente está justificada.
Herramientas como Pacemaker y Corosync siguen siendo el estándar de producción para la agrupación de alta disponibilidad basada en Linux. Cuando se configuran correctamente con fencing STONITH, proporcionan un failover automático confiable que previene los escenarios de cerebro dividido (split-brain), el modo de falla donde ambos nodos creen que son el primario y comienzan a aceptar escrituras conflictivas.
La Única Práctica que Lo Cambia Todo
Los simulacros de failover programados. No ejercicios de mesa. No revisar el runbook en una reunión. Pruebas de failover reales y controladas ejecutadas en un calendario definido, trimestralmente como mínimo para cualquier sistema donde los objetivos de RTO y RPO sean materiales para el negocio.
Un simulacro de failover sirve tres propósitos simultáneamente: valida que el mecanismo técnico de failover funciona según lo diseñado, le da al equipo de operaciones familiaridad procesal con el proceso de recuperación antes de necesitarlo bajo estrés, y revela la deriva de configuración: cambios en el entorno de producción que han roto los supuestos del plan de recuperación ante desastres sin que nadie lo haya notado.
Cada implementación de alta disponibilidad de Solvanta incluye objetivos de RTO y RPO definidos antes de la implementación, un runbook probado para cada escenario de falla, y simulacros trimestrales programados que se tratan como mantenimiento de infraestructura requerido, no como ejercicios opcionales. Los objetivos que ponemos en las propuestas son objetivos que hemos demostrado, no estimado.
Punto de Partida: Audita Tu Estado Actual
Si tu organización tiene objetivos de RTO y RPO pero no ha ejecutado una prueba de failover en los últimos seis meses, el punto de partida es directo: programa una. Identifica el escenario de falla que más te preocupa, falla del servidor de base de datos primario, pérdida del centro de datos, partición de red, y ejecuta una prueba controlada contra él.
Los resultados casi con certeza revelarán brechas. Ese es el objetivo. Una brecha descubierta en un simulacro programado cuesta una tarde. La misma brecha descubierta durante un incidente real cuesta órdenes de magnitud más.
Si necesitas ayuda para diseñar la prueba, interpretar lo que significan los resultados o cerrar las brechas que la prueba revela, ese es exactamente el tipo de trabajo que hacemos en Solvanta. La conversación es gratuita y no requiere ningún compromiso.