Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are two of the most cited metrics in infrastructure planning. They appear in vendor proposals, compliance documentation, and business continuity plans across virtually every industry. They are also, in many organizations, largely aspirational — numbers that reflect what teams hope will happen during a disaster rather than what has been demonstrated to happen.
A study by the Disaster Recovery Preparedness Council found that 73% of companies are inadequately prepared for disasters despite having documented recovery plans. That gap between documented and demonstrated readiness is one of the most consistent patterns we encounter in real infrastructure work.
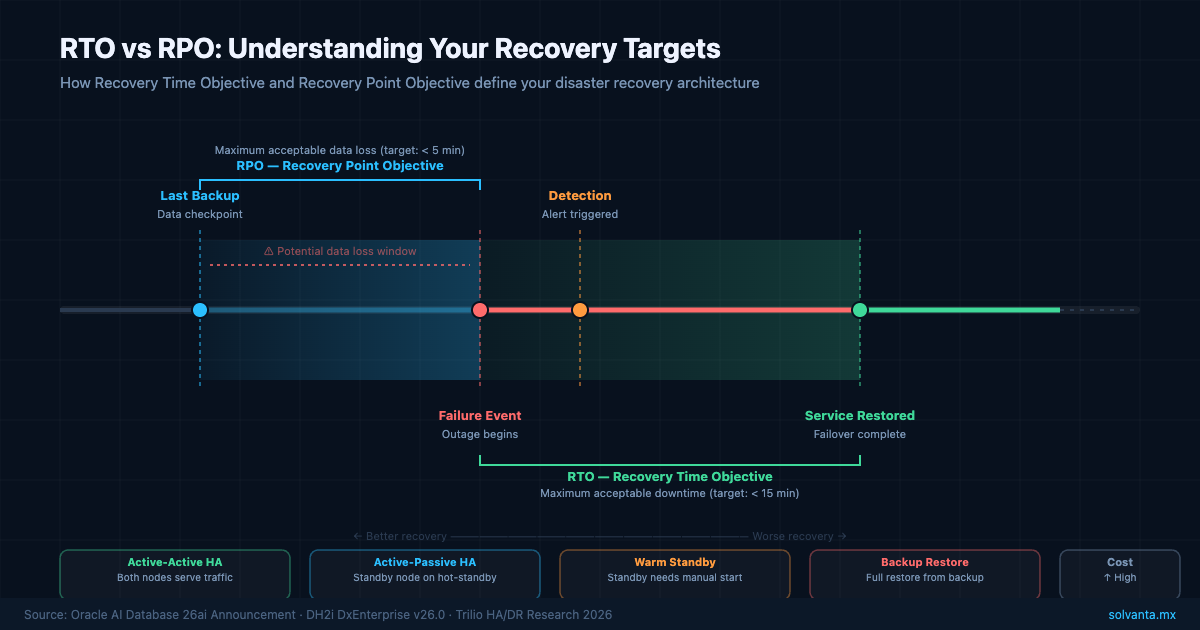
What RTO and RPO Actually Measure
RTO defines the maximum acceptable time between a failure and the restoration of service. RPO defines the maximum acceptable data loss — measured in time — between the last recoverable backup or replica and the point of failure.
An RTO of 15 minutes means your team commits to having services restored within a quarter-hour of a qualifying incident. An RPO of 5 minutes means no more than 5 minutes of data can be permanently lost. Both figures sound straightforward until you examine what achieving them actually requires at the infrastructure level.
A 15-minute RTO for a database server implies that failover is automatic, that the standby node is already synchronized, that DNS or IP cutover completes in seconds, and that the application tier reconnects cleanly — all without human intervention beyond initiating the process. If any of those assumptions breaks down, the RTO clock keeps running.
Where Plans Typically Break Down
The most common failure mode is not a technical one. It is an operational one: the failover architecture exists, but the procedures for activating it have never been executed under realistic conditions. Runbooks become outdated. Credentials expire. A configuration change made six months ago breaks an assumption the DR plan was built on. Nobody notices until the plan is needed.
The second most common failure mode is replication lag. Many organizations run master-replica database setups and assume their RPO is near-zero because replication is configured. In practice, replication lag under load can be significantly higher than under normal conditions — meaning the replica may be further behind at the exact moment a failover is triggered than at any other time.
Oracle’s recent announcement of its AI Database 26ai platform highlighted this precisely: their Platinum-tier availability offering achieves typical failover times under 30 seconds specifically because it is engineered around the failure modes that cause conventional DR to miss targets. Achieving sub-minute RTO at scale requires explicit architectural decisions, not default configurations.
Active-Active vs. Active-Passive: The Architecture Question
The choice between active-passive and active-active cluster design has significant implications for both RTO and RPO targets. In an active-passive setup, the secondary node is standing by but not serving traffic. Failover requires detection, decision, and switchover — each of which adds time. In an active-active setup, both nodes are serving traffic and data is synchronized bidirectionally. Failover, if it happens, is often transparent to the application layer.
Active-active architectures are more complex to implement and require careful handling of write conflicts, but they offer the lowest achievable RTO — often measured in seconds rather than minutes. For workloads where downtime has direct revenue impact, the engineering investment is usually justified.
Tools like Pacemaker and Corosync remain the production standard for Linux-based high-availability clustering. When properly configured with STONITH fencing, they provide reliable automatic failover that prevents split-brain scenarios — the failure mode where both nodes believe they are primary and begin accepting conflicting writes.
The One Practice That Changes Everything
Scheduled failover drills. Not table-top exercises. Not reviewing the runbook in a meeting. Actual, controlled failover tests executed on a defined schedule — quarterly at minimum for any system where RTO and RPO targets are material to the business.
A failover drill serves three purposes simultaneously: it validates that the technical failover mechanism works as designed, it gives the operations team procedural familiarity with the recovery process before they need it under stress, and it reveals configuration drift — changes to the production environment that have broken DR assumptions without anyone realizing it.
Every Solvanta high-availability deployment includes defined RTO and RPO targets established before implementation, a tested runbook for each failure scenario, and scheduled quarterly drills that are treated as required infrastructure maintenance rather than optional exercises. The targets we put in proposals are targets we have demonstrated, not estimated.
Starting Point: Audit Your Current State
If your organization has RTO and RPO targets but has not run a failover test within the past six months, the starting point is straightforward: schedule one. Identify the failure scenario you are most concerned about — primary database failure, datacenter loss, network partition — and execute a controlled test against it.
The results will almost certainly reveal gaps. That is the point. A gap discovered in a scheduled drill costs an afternoon. The same gap discovered during an actual incident costs orders of magnitude more.
If you need help designing the test, interpreting what the results mean, or closing the gaps the test reveals, that is exactly the kind of work we do at Solvanta. The conversation is free and does not require a commitment.